Veri Ambarı (Data Warehouse) Nedir? SCD Türleri, Data Lake ve Veri Ambarı Mimarisi
Veri ambarı (Data Warehouse) nedir? Kimball ve Inmon yaklaşımları, Data Mart yapıları, SCD Type 1 ve Type 2 örnekleri ile veri ambarı mimarisini detaylı öğrenin.
Veri Ambarı (Data Warehouse) Nedir? SCD Türleri, Kimball ve Inmon Yaklaşımları
Veri analitiği ve iş zekâsı süreçleri son yıllarda şirketlerin karar alma mekanizmalarının merkezine yerleşti. Günümüzde işletmeler, satışlardan müşteri hareketlerine kadar her alanda devasa veriler topluyor ve operasyonel sistemleri üzerinden hayatlarına devam ediyor. Ancak bu klasik operasyonel sistemlerin en büyük problemi, genellikle verinin sadece 'o anki' en güncel hâlini tutmaya odaklanmalarıdır. İşte tam bu noktada, yapılandırılmış verilerin güvenilir ve merkezi adresi olan Veri Ambarı Data Warehouse) ve verilerdeki bu tarihsel değişimleri sistemli bir şekilde yönetmemizi sağlayan SCD Slowly Changing Dimension) yapıları devreye giriyor.
1. Veri Ambarı Nedir?
Veri ambarı, bir kurumun ERP sistemleri, CRM verileri, Excel tabloları gibi farklı operasyonel sistemlerden gelen verilerinin karar destek sistemleri, raporlama ve veri analizi amacıyla toplandığı, temizlendiği ve belirli bir standartta saklandığı merkezi bir veri deposudur.
Elimizdeki sistemlere ayrı ayrı bağlanıp veriyi hataya açık ve zaman alan bir yöntemle toplamak yerine veri ambarı bu verileri ilişkisel (relational) bir yapıda birleştirir. Tek bir sorgu ile tüm veriyi bir arada görmemizi sağlar. Bu yüzden veri ambarına “Tekil Doğruluk Kaynağı Single Source Of Truth)” da denir.
1.1 Veri Ambarı Mimarisi Yaklaşımları
Veri ambarı tasarımında iki farklı yaklaşım bulunur.
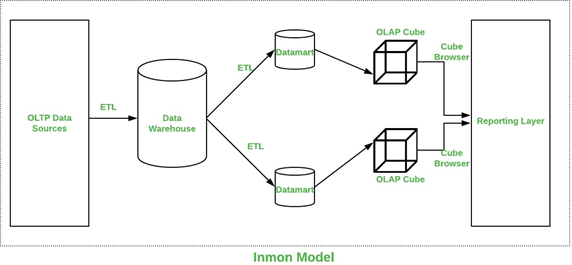
1.1.1 Bill Inmon Yaklaşımı
Veri ambarının babası sayılan Bill Inmonʼa göre veri ambarı, “yukarıdan aşağıya (top-down)” bir mimariyi benimsemelidir. Bu yöntemde kurumun tüm veri kaynaklarından elde edilen veriler öncelikle merkezi bir kurumsal veri ambarında
toplanır. Sonrasında, bu ana merkezden beslenen ve belirli departmanların veya iş alanlarının ihtiyaçlarına yönelik tasarlanan daha küçük çaplı Data Mart türetilir.
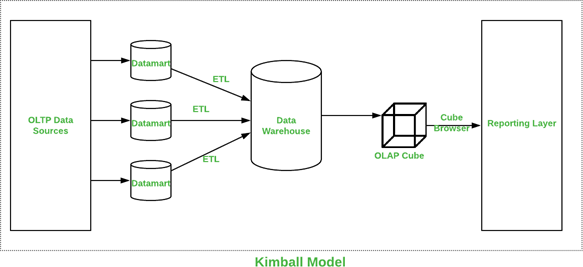
1.1.2 Ralph Kimball Yaklaşımı
Ralph Kimballʼın yaklaşımına göre veri ambarı, “aşağıdan yukarıya (bottom-up)” ilerleyen, agile ve modüler bir boyutlu modelleme (dimensional modeling) mantığına dayanır. Yani, tüm kurumu tek seferde, karmaşık bir şekilde modellemek yerine; öncelikle belirli iş süreçlerine odaklanan ve son kullanıcıların kolayca rapor alabileceği denormalize yıldız şema (star schema - Fact, Dimension) yapısında Data Mart oluşturulmasını savunur.
1.1.3 Yaklaşımlar Arası Farklar
İki yöntem arasındaki en temel fark inşa yönü ve kullanılan veri modelleme mimarisidir. Inmon önce bütünsel ve karmaşık bir veri ambarı kurup daha sonra parçalara bölerken; Kimball işe doğrudan kullanıcı odaklı küçük parçalarla başlar ve bütünü bu parçaları birleştirerek oluşturur. Bu sebeple Inmon modeli uzun kurulum süresi ve yüksek başlangıç maliyeti gerektirirken; Kimball modeli daha hızlı sonuç veren, iş birimlerinin acil ihtiyaçlarına çabuk yanıt verebilen ve maliyeti zamana yayan bir yapı sunar.
Türkiyeʼde genellikle bütçe kısıtları, acil raporlama ihtiyaçları, PowerBI gibi görselleştirme araçlarının yaygınlığı nedeniyle Kimball modeli daha sık tercih edilir.
1.2 Veri Ambarı Katmanları
Modern bir veri ambarı mimarisi genellikle verinin ham halden rafine edilmiş bilgiye dönüşmesini sağlayan katmanlı (layered) bir yapıdan oluşur.
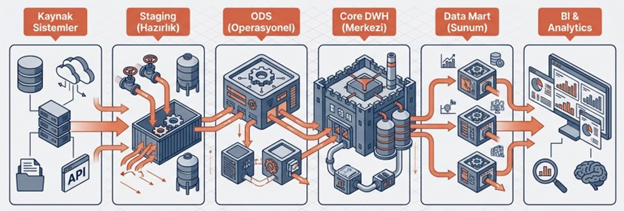
1.2.1 Staging Katmanı (Hazırlık)
Bu katman verinin kaynak sistemlerden ilk geldiği “tampon” bölgedir.
- Veriler buraya birebir kopyalanır.
- Temel amaç veriyi bir an önce kaynak sistemlerden çekerek canlı sistem üzerindeki yükü kaldırmaktır.
- Veri temizleme, tip dönüşümleri ve ilk validasyonlar burada yapılır.
- Karmaşık hesaplamalardan önce veri burada güvenli bir alana alınmış olur.
- Tablolar arasında ilişkiler kurularak farklı formatlardaki verilere de ulaşılır.
1.2.2 ODS Katmanı (Operational Data Store)
Burası kaynak sistemlerin anlık veya çok yakın zamanlı bir kopyasını tutar.
- ODS katmanında veriler kalıcı olabilir ve üzerine yazılarak güncellenir.
- Tarihsel veri tutmaz, sadece “şu anki” durumu yansıtır.
1.2.3 Core (Merkezi) Veri Ambarı Katmanı
Verinin tarihçeli, entegre ve temizlenmiş olarak saklandığı ana depodur.
- Genelde son kullanıcılar tarafından analiz, görselleştirme vb. yapmak için kullanılır.
1.2.4 Data Mart Katmanı (Sunum)
Son kullanıcıların ve raporlama araçlarının Power BI, Tableau vb.) bağlandığı katmandır.
- Eğer eldeki veri çok büyükse ya da farklı amaçlar için kullanılmak isteniyorsa Core katmanından alınan veriler belirli iş birimlerine Satış, İK, Finans vb.) özel hale getirilir.
- Sadece gerekli olan tablolar yer aldığından kullanıcı dostu bir kullanım sağlar.
- Sorgu performansı için Denormalize edilir.
- Genellikle Kimball metodolojisindeki Yıldız Şema yapısında Fact ve Dimension tabloları burada bulunur.
- Veri ambarının bir alt kümesi gibidir.
2. Slowly Changing Dimensions (SCD)
Veri ambarında, zaman içinde yavaşça değişen boyut verilerinin (müşteri adresi, departman bilgisi, işe giriş-çıkış gibi) nasıl güncelleneceğini ve tarihsel olarak nasıl yönetileceğini belirleyen veri modelleme konseptine Slowly Changing Dimensions denir.
Kaynak sistemden gelen veriler, veri ambarındaki mevcut verilerle kıyaslanarak sadece değişen kayıtlar tespit edilir ve seçilen stratejiye göre işlenir.
Bu yapı hem veri ambarının performanslı çalışmasını sağlar hem de verinin geçmişe dönük versiyonlanmasını mümkün kılar.
Bu yapıyı daha yakından görebilmek için küçük bir örnek yapalım. Bu aşamalarda SQL Server ve Visual Studio üzerinde SQL Server Integration Services SSIS) eklentisinden yararlanacağız.
2.1 Kaynak ve Staging Tablolarının Oluşturulması
Örneğe başlarken öncelikle kaynak veriyi temsil edecek olan Emp_Source tablosunu oluşturalım. Bu tabloda çalışanların EmpId, FirstName, LastName ve Designation bilgileri yer alıyor.
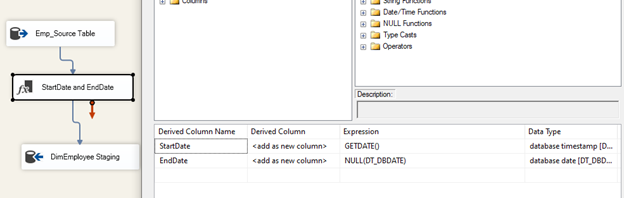
Verinin tarihsel değişimini veri ambarında yönetebilmek için SSIS üzerinde bir “Derived Column” bileşeni kullanarak akışa StartDate ve EndDate sütunlarını ekleyelim.
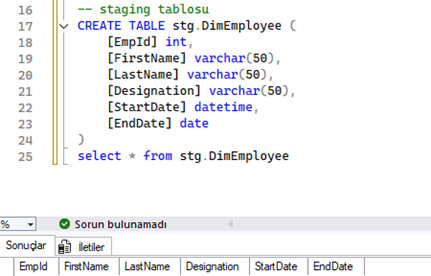
Ardından veriyi aktaracağımız DimEmployee isimli staging tabloyu hazırlayalım.
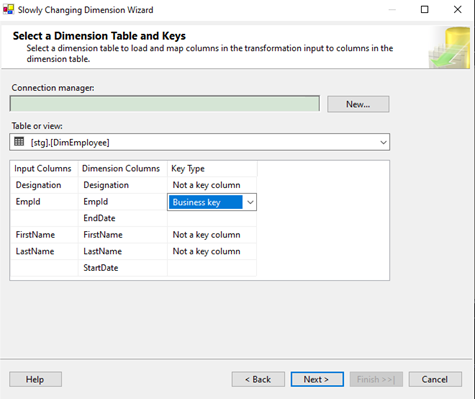
SSIS'teki “Slowly Changing Dimension Wizard” SCD Sihirbazı) aracılığıyla iki tablo arasındaki ortak anahtar olan EmpId sütununu “Business Key” olarak belirleyelim. Burada Business Key verinin kimliği görevi görüyor ve yeni veri akışını kontrol edebilmemizi sağlıyor.
2.2 SCD Type 1 (Changing Attributes)
Geçmişe dönük veri tarihçesinin önemli olmadığı ve sadece en güncel bilginin tutulmasının yeterli olduğu durumlarda kullanılır. Kaynakta bir veri değiştiğinde, veri ambarındaki mevcut eski kaydın üzerine doğrudan yeni bilgi yazılır ve böylece eski veri tamamen kaybolur. Bu yöntemde tarihçe tutulmaz; değişikliğe uğramayan kayıtlara ise dokunulmadan pas geçilir.
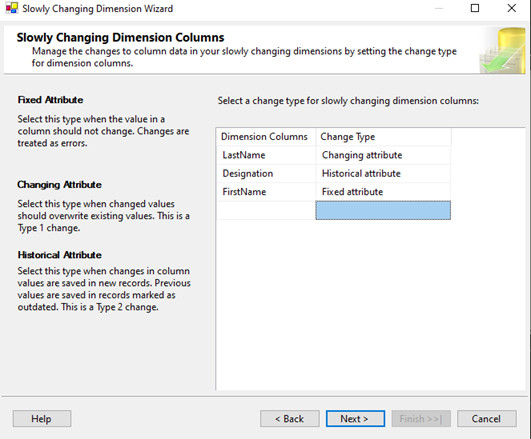
- Örnek Senaryo: Çalışanların soyadı değişiklikleri Type 1 olsun. SCD sihirbazında LastName sütununu “Changing attribute” olarak işaretleyelim.
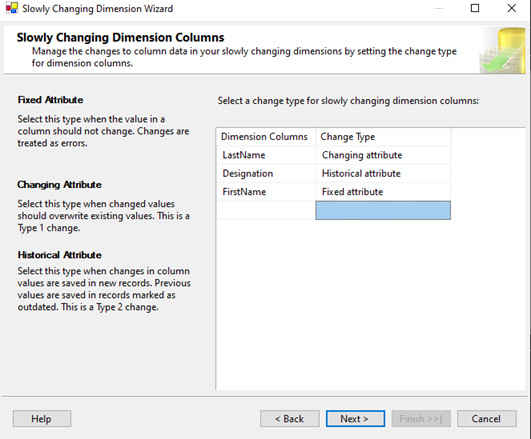
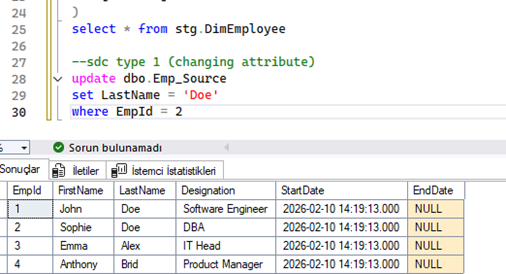
- Test ve Sonuç: Emp_Source tablosunda EmpId'si 2 olan Sophie'nin soyadını “Doe” olarak güncelleyelim. SSIS paketini çalıştırdığımızda, tarihsel bir veri tutulmadan doğrudan eski soyadının üzerine yazıldığını görülür. Sonuç tablosunda yeni bir satır eklenmez, sadece ilgili çalışanın LastName değeri değişir.
2.2 SCD Type 2 (Historical Attribute)
Değişikliklerin zaman içindeki tüm versiyonlarının eksiksiz olarak kayıt altına alınmasını sağlayan ve veri ambarlarında en sık tercih edilen yöntemdir. Kaynak sistemde bir değişiklik saptandığında eski kaydın üzerine yazılmaz; bunun yerine eski kayıt pasife çekilerek korunur ve yeni veri, “aktif” statü ile veri tabanına yepyeni bir satır olarak eklenir. Bu sayede verini tüm geçmiş adımları izlenebilir ve tarihsel raporlamalar sorunsuz bir şekilde yapılabilir.
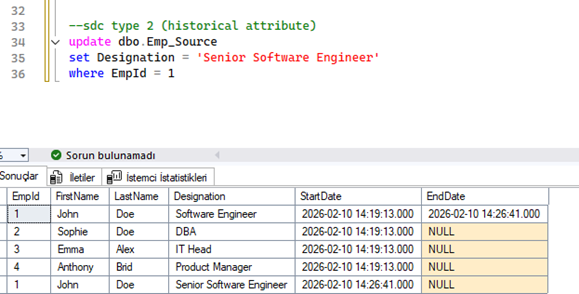
- Örnek Senaryo: Çalışanların unvan Designation) değişikliklerinin tarihçesi tutulmak istensin. Bu nedenle Designation sütunu “Historical attribute” olarak atanır.
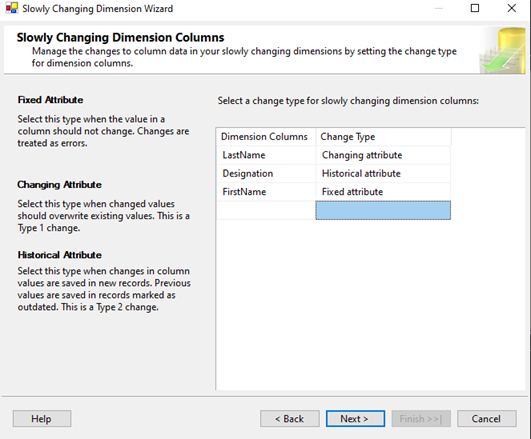
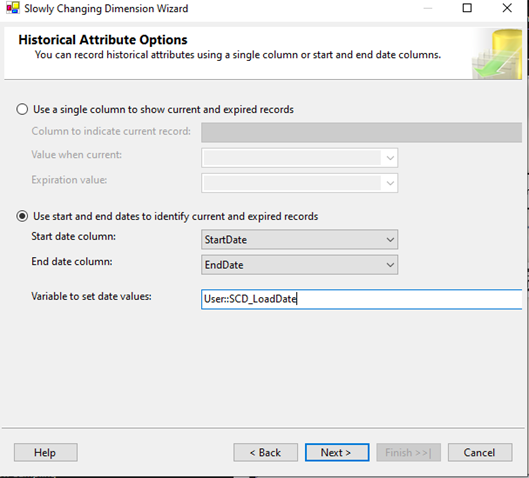
- Tarih Ayarları: Sihirbaz üzerinden başlangıç ve bitiş tarihlerini kontrol etmek için StartDate ve EndDate sütunları seçilir.
- Test ve Sonuç: EmpId'si 1 olan çalışana John Doe) terfi vererek unvanı “Senior Software Engineer” yapılmak istensin. Süreç çalıştırıldığında tabloya John Doe için iki kayıt oluşur: İlk kaydın EndDate kısmına değişim tarihi 2026 02 10 14 26 41.000) yazıldı ve eski unvan pasife çekildi. Yeni unvan ise yeni bir StartDate ve NULL EndDate ile aktif kayıt olarak sisteme eklendi.
2.3 SCD Fixed Attribute:
Bu yaklaşımda, veri ambarında ilk kez yazılan boyut alanının bir daha asla değişmeyeceği varsayılır. Kaynak sistemde o veriye dair sonradan bir değişiklik yapılsa dahi, veri ambarı bu değişikliği dikkate almaz ve ilk yüklenen orijinal kaydı tutmaya devam eder. Genellikle müşterinin “doğum tarihi” veya “sisteme ilk kayıt olduğu tarih” gibi doğası gereği sabit kalması gereken değişmez nitelikler için kullanılır.
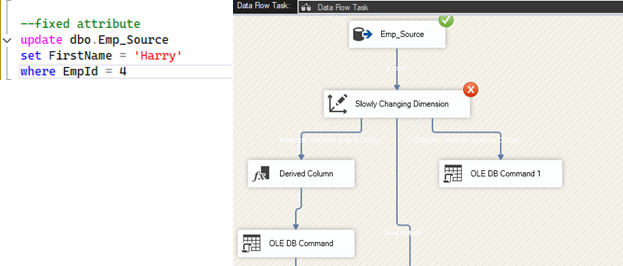
- Örnek Senaryo: Çalışanın ilk adı FirstName) değişmemesi gereken bir veri olsun. Bu sütunu “Fixed attribute” olarak tanımlanır.
- Test ve Sonuç: Sistemi test etmek için EmpId'si 4 olan çalışanın ilk adını 'Harry' olarak değiştirilsin. Sonuç tam da beklenildiği gibi olur: SSIS veri akışı, değişmemesi gereken bir değerde değişiklik tespit ettiği için hata verir Slowly Changing Dimension bileşeni üzerinde kırmızı bir çarpı belirdi) ve süreç durur.
3. Veri Ambarından Veri Gölüne: Modern Veri Mimarilerine Bakış
3.1 Veri Gölü (Data Lake) Nedir?
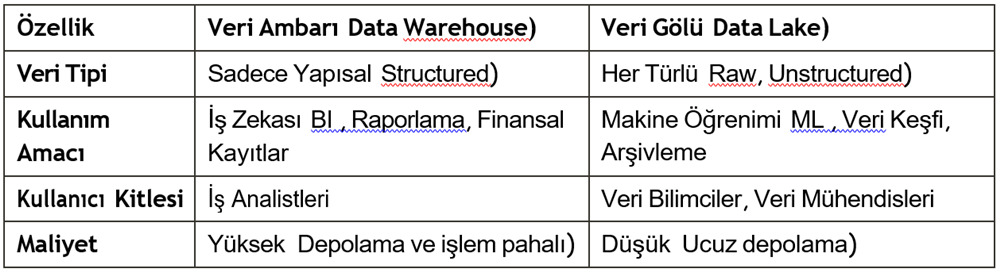
Veri ambarı yapısal (structured) verilere ve ilişkisel tablolara odaklanırken; Veri Gölü, verilerin hiçbir işlemden geçmeden, ham (raw) formatta “döküldüğü” merkezi bir depolama alanıdır.
- Sadece ilişkisel veriler değil; yarı yapısal JSON, XML) ve yapısal olmayan (video, ses, loglar) devasa veriler Big Data) burada barınabilir.
- Veri ambarındaki gibi baştan bir şema (tablo yapısı) tasarımı gerekmez. Veriler olduğu gibi atılır ve şeması ancak analiz edileceği zaman oluşturulur.
3.1.1 Veri Gölünün Avantajları ve Riskleri
Veri gölleri devasa verileri depolamak için harika olsa da, yönetimi dikkat gerektirir. Her türlü veriyi saklama imkanı sunar, veri tipi kısıtlaması yoktur.
- Veri ambarına kıyasla çok daha ekonomik bir saklama maliyeti sunar.
- Veri bilimciler, ML modellerini eğitmek için ihtiyaç duydukları geniş çaplı ve ham veriye erişim için kullanılır.
- Doğru bir yönetim uygulanmazsa veri çöplüğüne (data swamp) dönüşebilir.
- SQL kullanan iş kullanıcılarının veriyi sorgulaması zordur.
- Doğrudan raporlamaya uygun değildir.
3.1.2 Hangisi Tercih Edilmeli?
Veri ambarı ve veri gölü teknolojileri birbirinin rakibi değil, aslında çok farklı amaçlara hizmet eden tamamlayıcılardır. Bu yüzden yakın gelecekte veri göllerinin veri ambarlarının yerini tamamen alacağını söyleyemeyiz.
3.2 Geleneksel Veri Ambarı Ölüyor mu?
Geleneksel veri ambarı artık “en güncel” teknoloji olarak kabul edilmiyor; ancak bu teknolojinin öldüğü anlamına da gelmiyor. Bunun yerine, veri ambarı kavramı "Modern Veri Yığını" Modern Data Stack) içinde evrimleşiyor.
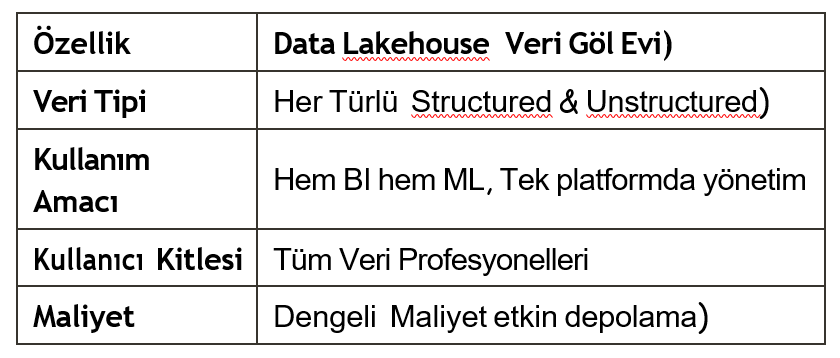
Günümüzün en trend yaklaşımı, veri ambarının güvenilirliği (veri kalitesi, işlem tutarlılığı) ile veri gölünün esnekliğini (ucuz depolama, ham veri) birleştiren Data Lakehouse Veri Göl Evi) mimarisidir. Ayrıca, geleneksel ETL Extract, Transform, Load) süreçleri, bulut bilişimin veri işleme gücü sayesinde yerini hızla ELT Extract, Load, Transform) süreçlerine bırakmaktadır. Veri önce hızlıca göle yüklenmekte, ardından hedef sistemin kendi işlem gücüyle dönüştürülmektedir.
Betül TOYOĞLU